التحليل العاملي
يستخدم التحليل العاملي Factor Analysis بشكل أساسي لاختزال أو اختصار البيانات data reduction أو اكتشاف البنية structure detection.
- الغرض من اختزال البيانات data reduction هو إزالة المتغيرات الزائدة (شديدة الارتباط) من ملف البيانات، وربما استبدال ملف البيانات بأكمله بعدد أقل من المتغيرات غير المرتبطة.
- الغرض من اكتشاف البنية structure detection هو فحص العلاقات الأساسية (أو الكامنة) بين المتغيرات.
طرق التحليل العاملي
يحتوي إجراء التحليل العاملي على عدة طرق ممتدة لإنشاء الحل المطلوب.
إجراء اختزال البيانات
تبدأ طريقة استخلاص المكونات الرئيسية principal components extraction بإيجاد مجموعة خطية من المتغيرات (مكون) component التي تمثل أكبر قدر ممكن من التباين في المتغيرات الأصلية. ثم يتم إيجاد مكونًا آخر يمثل أكبر قدر ممكن من التباين variation المتبقي وغير مرتبط بالمكون السابق، وتستمر بهذه الطريقة حتى يتم إيجاد العديد من المكونات مثل المتغيرات الأصلية. عادة، ستأخذ بعض المكونات في الاعتبار معظم التباين، ويمكن استخدام هذه المكونات لتحل محل المتغيرات الأصلية. غالبًا ما تستخدم هذه الطريقة لتقليل عدد المتغيرات في ملف البيانات.
إجراء الكشف عن الهيكل
تذهب طرق التحليل العاملي الأخرى خطوة أخرى إلى الأمام بإضافة افتراض أن بعض التباين في البيانات لا يمكن تفسيره بالمكونات (تسمى عادةً العوامل في طرق الاستخلاص الأخرى). نتيجة لذلك، يكون التباين الكلي total variance الذي يفسره الحل أصغر؛ ومع ذلك، فإن إضافة هذه البنية إلى النموذج العاملي تجعل هذه الطرق مثالية لفحص العلاقات بين المتغيرات.
مع أي طريقة استخلاص، فإن السؤالين اللذين يجب أن يحاول الحل الجيد الإجابة عليهما هما “كم عدد المكونات (العوامل) factors اللازمة لتمثيل المتغيرات؟” و “ماذا تمثل هذه المكونات؟”
استخدام التحليل العاملي لاختزال البيانات
ترغب محللة الصناعة في توقع مبيعات السيارات من مجموعة من المتنبئين. ومع ذلك، فإن العديد من المتنبئين مترابطة، ويخشى المحلل من أن هذا قد يؤثر سلبًا على نتائجها.
هذه المعلومات واردة في ملف car_sales.sav. راجع موضوع “ملفات الأمثلة” للحصول على مزيد من المعلومات. استخدم التحليل العاملي مع استخراج المكونات الرئيسية principal components extraction لتركيز التحليل على مجموعة فرعية يمكن إدارتها من المتنبئين predictors.
تشغيل التحليل العاملي
لإجراء التحليل العاملي لاستخلاص المكونات الرئيسية principal components factor analysis:
1. اختر من القوائم: تحليل> اختزال الأبعاد> عاملي …
Analyze > Dimension Reduction > Factor…
يظهر مربع حوار التحليل العاملي كما يلي:
2. إذا لم تعرض قائمة المتغيرات تسميات المتغير بحسب ترتيب الملفات، فانقر بزر الماوس الأيمن في أي مكان في قائمة المتغيرات variables ومن قائمة السياق context، اختر عرض تسميات المتغيرات Display Variable Labels والفرز حسب ترتيب الملفات Sort by File Order.
3. حدد الحقول من “نوع السيارة” Vehicle type ولغاية “كفاءة استخدام الوقود” Fuel efficiency كمتغيرات التحليل analysis variables.
4. انقر فوق استخلاص أو استخراج Extraction.
يظهر مربع حوار الاستخراج كما يلي:
5. حدد مخطط سكري Scree plot.
6. انقر فوق متابعة Continue.
7. انقر فوق استدارة Rotation في مربع حوار تحليل العوامل Factor Analysis.
يظهر مربع حوار التدوير Rotation كما يلي:
8. حدد Varimax في مجموعة الطريقة Method.
9. انقر فوق متابعة Continue.
10. انقر فوق الدرجات Scores في مربع حوار تحليل العوامل Factor Analysis.
يظهر مربع حوار درجات العوامل كما يلي:
11. حدد “حفظ كمتغيرات” Save as variables و”عرض مصفوفة معاملات درجة العامل” Display factor score coefficient matrix.
12. انقر فوق متابعة Continue.
13. انقر فوق “موافق” OK في مربع حوار تحليل العوامل Factor Analysis.
المجتمعات Communalities
الشكل التالي يبين جدول المجتمعات Communalities:
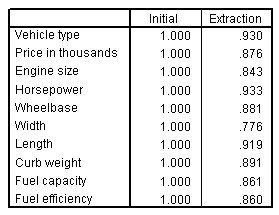
تشير المجتمعات إلى مقدار التباين في كل متغير يتم احتسابه. المجتمعات الأولية هي تقديرات للتباين في كل متغير يتم تفسيره من خلال جميع المكونات أو العوامل. بالنسبة لاستخراج المكونات الرئيسية، يكون هذا دائمًا مساويًا لـ 1.0 لتحليلات الارتباط.
مجتمعات الاستخراج Extraction communalities هي تقديرات للتباين في كل متغير تم حسابه بواسطة المكونات. جميع العناصر المشتركة في هذا الجدول عالية، مما يشير إلى أن المكونات المستخرجة تمثل المتغيرات جيدًا. إذا كانت أي قواسم مشتركة منخفضة جدًا في استخراج المكونات الرئيسية، فقد تحتاج إلى استخراج مكون آخر.
تفسير التباين الكلي
الشكل التالي يبين تفسير التباين الكلي، الحل الأولي Total variance explained, initial solution:
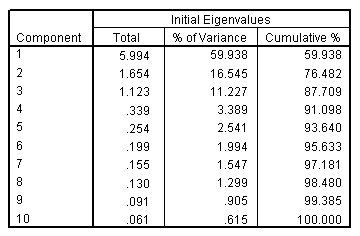
يتم عرض التباين الموضح بواسطة الحل الأولي والمكونات المستخرجة والمكونات المدورة. يوضح هذا القسم الأول من الجدول القيم الذاتية الأولية Initial Eigenvalues.
يعطي عمود الإجمالي Total القيمة الذاتية، أو مقدار التباين في المتغيرات الأصلية التي يمثلها كل مكون. ويعطي عمود النسبة المئوية للتباين % of Variance النسبة، معبرًا عنها كنسبة مئوية، للتباين الذي يمثله كل مكون إلى إجمالي التباين في جميع المتغيرات. كما يعطي عمود النسبة المئوية التراكمية Cumulative % النسبة المئوية للتباين الذي تم حسابه بواسطة مكونات n الأولى. على سبيل المثال، النسبة المئوية التراكمية للمكون الثاني هي مجموع النسبة المئوية للتباين للمكونين الأول والثاني.
بالنسبة للحل الأولي، هناك العديد من المكونات مثل المتغيرات، وفي تحليل الارتباطات، مجموع القيم الذاتية eigenvalues يساوي عدد المكونات. لقد طلبت استخراج قيم eigenvalues الأكبر من 1، لذا فإن المكونات الرئيسية الثلاثة الأولى تشكل الحل المستخرج.
الشكل التالي يبين تفسير التباين الكلي: المكونات المستخرجة Total variance explained, extracted components:
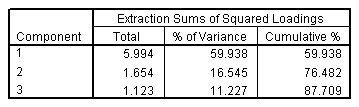
يوضح القسم الثاني من الجدول المكونات المستخرجة. يفسر ما يقرب من 88٪ من التباين في المتغيرات العشرة الأصلية، لذلك يمكنك تقليل تعقيد مجموعة البيانات بشكل كبير باستخدام هذه المكونات، مع فقد المعلومات بنسبة 12٪ فقط.
الشكل التالي يبين تفسير التباين الكلي – تدوير المكونات Total variance explained, rotated components:
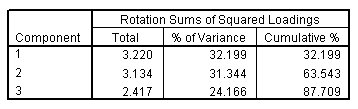
يحافظ التدوير على النسبة المئوية التراكمية للتباين الموضحة بواسطة المكونات المستخرجة، ولكن هذا التباين ينتشر الآن بشكل متساوٍ على المكونات. تشير التغييرات الكبيرة في الإجماليات الفردية إلى أن مصفوفة المكون المدورة ستكون أسهل في التفسير من المصفوفة غير المدورة.
مخطط Scree
الشكل التالي يبين مخطط Scree:
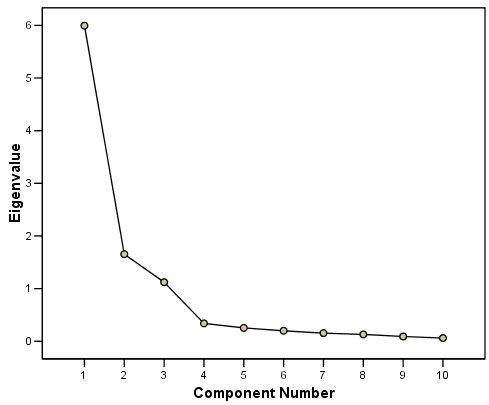
يساعدك مخطط Scree على تحديد العدد الأمثل للمكونات. يتم رسم القيمة الذاتية لكل مكون في الحل الأولي. بشكل عام، تريد استخراج المكونات الموجودة على المنحدر الحاد. لا تساهم المكونات الموجودة على المنحدر الضحل كثيرًا في الحل. يحدث الانخفاض الكبير الأخير بين المكونين الثالث والرابع، لذا فإن استخدام المكونات الثلاثة الأولى يعد اختيارًا سهلاً.
مصفوفة المكونات المدورة
الشكل التالي يبين مصفوفة المكونات المدورة Rotated component matrix:
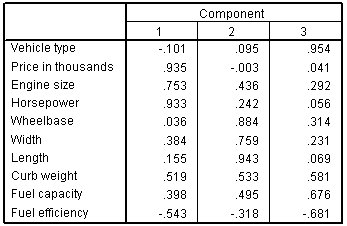
تساعدك مصفوفة المكونات المدورة على تحديد ما تمثله المكونات. المكون الأول هو الأكثر ارتباطًا بالسعر بالآلاف Price in thousands والقدرة الحصانية Horsepower. ومع ذلك، فإن السعر بالآلاف هو أفضل تمثيل لأنه أقل ارتباطًا بالمكونين الآخرين. المكون الثاني هو الأكثر ارتباطًا بالطول Length. يرتبط المكون الثالث ارتباطًا وثيقًا بنوع السيارة Vehicle type. يشير هذا إلى أنه يمكنك التركيز على السعر بالآلاف، والطول ، ونوع السيارة في مزيد من التحليلات، ولكن يمكنك القيام بعمل أفضل من خلال حغظ درجات المكونات.
مصفوفة معامل درجات المكون
الشكل التالي يبين مصفوفة معامل درجات المكون Component score coefficient matrix:
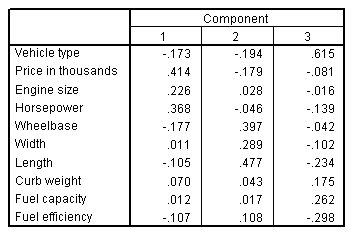
لكل حالة وكل مكون، يتم حساب درجة المكون بضرب قيم المتغيرات المعيارية للحالة (محسوبة باستخدام الحذف القائم على القائمة) في معاملات درجة المكون. تمثل متغيرات درجات المكونات الثلاثة الناتجة، ويمكن استخدامها بدلاً من، المتغيرات العشرة الأصلية مع فقدان المعلومات بنسبة 12 ٪ فقط.
يُفضل أيضًا استخدام المكونات المحفوظة على استخدام السعر بالآلاف، والطول، ونوع السيارة لأن المكونات تمثل جميع المتغيرات العشرة الأصلية، والمكونات غير مرتبطة ببعضها البعض خطيًا.
على الرغم من أن الارتباط الخطي بين المكونات مضمون ليكون 0، يجب أن تنظر إلى مخطط درجات المكونات للتحقق من القيم المتطرفة outliers والارتباطات غير الخطية nonlinear associations بين المكونات.
مصفوفة المخطط المبعثر لدرجات المكونات
لإنتاج مصفوفة المخطط المبعثر لدرجات المكون:
1. اختر من القوائم: الرسوم البيانية> منشئ المخطط …
يظهر منشئ المخطط كما يلي:
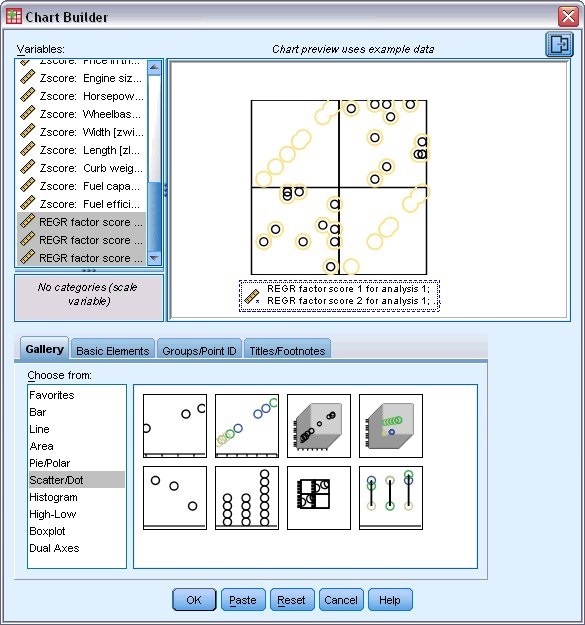
2. انقر فوق علامة التبويب معرض Gallery، وحدد مبعثر / نقطة Scatter/Dot لنوع المخطط، واسحب وأفلت أيقونة مصفوفة مخطط مبعثر Scatterplot Matrix في اللوحة.
3. حدد من REGR factor score 1 for analysis 1 ولغاية REGR factor score 3 for analysis 1 كمتغيرات المصفوفة matrix variables.
4. انقر فوق موافق OK.
الشكل التالي يبين مصفوفة مخطط التشتت لدرجات العوامل Scatterplot matrix of factor scores:
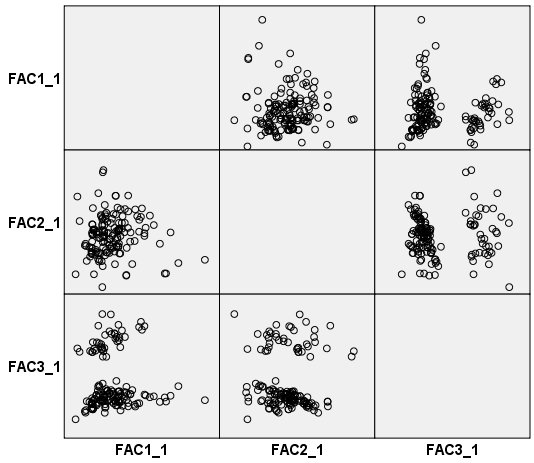
يُظهر المخطط الأولى في الصف الأول المكون الأول على المحور الرأسي مقابل المكون الثاني على المحور الأفقي، ويتبع ترتيب المخططات المتبقية من هناك.
توضح مصفوفة مخطط الانتشار أن المكون الأول له توزيع ملتوي skewed distribution، وذلك لأن السعر بالآلاف ملتوي. قد يؤدي استخراج المكونات الرئيسية باستخدام سعر محوّل لوغاريتميًا إلى نتائج أفضل. يتم تفسير الفصل الذي تراه في المكون الثالث من خلال حقيقة أن نوع السيارة Vehicle type هو متغير ثنائي binary variable. يبدو أن هناك علاقة بين المكونين الأول والثالث، نظرًا لوجود العديد من السيارات باهظة الثمن ولكن لا توجد “شاحنات فاخرة”. قد يتم تخفيف هذه المشكلة باستخدام سعر تم تحويله لوغاريتميًا، ولكن إذا لم يؤد ذلك إلى حل المشكلة، فقد ترغب في تقسيم الملف بحسب نوع السيارة.
خلاصة استخدام التحليل العاملي لاختزال البيانات
يمكنك تقليل حجم ملف البيانات من عشرة متغيرات إلى ثلاثة مكونات باستخدام التحليل العاملي مع استخراج المكونات الرئيسية. لاحظ أن تفسير التحليلات الإضافية يعتمد على العلاقات المحددة في مصفوفة المكون المدورة. هذه الخطوة من “الترجمة” تعقد الأمور قليلاً، لكن فوائد تقليل ملف البيانات واستخدام تنبؤات غير مرتبطة تفوق هذه التكلفة.
المصدر
- التحليل الإحصائي باستخدام برنامج SPSS، ترجمة وإعداد: د. م. مصطفى عبيد، مركز البحوث والدراسات متعدد التخصصات
- الموقع الرسمي لشركة IBM ® برنامج SPSS